基于Dify认识工作流引擎:状态机与上下文传递
一、从痛点到原理
1.1 开发工作中的痛点
在上一篇文章中,我们学习了 DAG 调度如何解决”任务依赖顺序”的问题。但当 DAG 引擎真正驱动节点运行时,又会面临新的工程难题:
- 状态管理混乱:
场景:一个节点正在运行,另一个线程也尝试启动它;或者一个成功完成的节点被重复触发。痛点:没有统一的状态约束,任意代码都可以将节点置为任意状态,非法的状态跃迁(如从 成功 直接变为 运行中)悄然发生,导致数据错乱和行为不可预期。
- 上下文数据传递困难:
场景:LLM 节点输出了一段摘要文本,下游的 HTTP 节点需要将这段文本作为请求体发送出去;知识检索节点找到了相关文档,LLM 节点需要将其拼入 Prompt 中。痛点:在多线程并发环境下,节点间如何安全、可靠地传递数据?直接使用全局变量会引发竞态条件,手动传参则导致节点间紧耦合。
- 并发写入冲突:
场景:A 节点和 B 节点并行执行,它们都在同一时刻尝试向共享存储写入结果。痛点:没有并发控制机制,后写入的数据会覆盖先写入的数据,或者两者的写入互相干扰,产生脏数据。
- 错误恢复无从下手:
场景:工作流执行到一半,因为某个节点失败或服务器重启,整个流程中断。痛点:无法判断哪些节点已完成、哪些未完成,只能从头重跑,代价极高。
结论:我们需要一个能够精确约束节点生命周期的状态机,以及一个支持并发安全读写的共享上下文(变量池),二者协同工作,才能让 DAG 引擎真正健壮地运转。
1.2 什么是状态机与变量池?
1.2.1 状态机的定义
什么是状态机?
状态机(State Machine),也称为有限状态机(Finite State Machine, FSM),是一种用来描述一个系统的行为模型,常用于描述对象在其生命周期内所有的可能状态以及状态之间如何转换。
状态机由一组状态、一组输入事件和一组转换规则组成。系统在任何时刻都处于一种状态,当输入事件发生时,根据当前状态和转换规则,系统可能会转移到另一种状态。
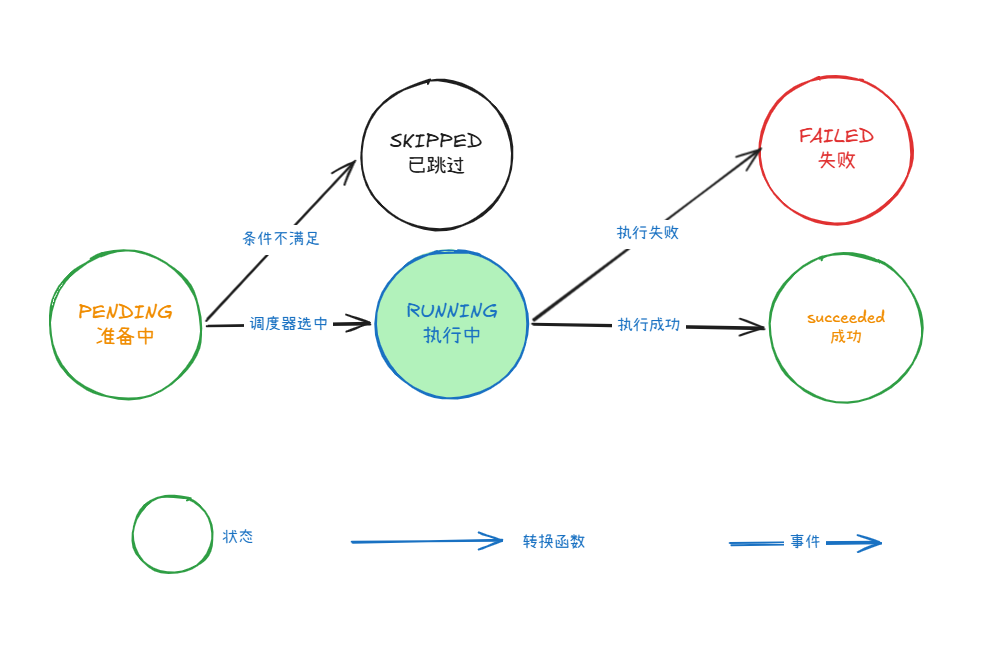
状态机主要包括以下几个核心部分:
| 要素 |
含义 |
业务映射 |
状态 (State) |
系统在某一时刻所处的”模式”。一个状态机至少要包含两个状态,例如工作流节点的 等待中、运行中、已成功。 |
PENDING(等待)/ RUNNING(执行中)/ SUCCEEDED(成功)/ FAILED(失败)/ SKIPPED(已跳过) |
事件 (Event) |
执行某个变换的触发条件(信号),例如”调度器选中节点执行”、”节点代码抛出异常”。 |
调度器选中节点、节点执行成功、节点抛出异常、条件分支判断为假 |
转换函数 (Transition) |
也叫转换函数,指从一个状态变化为另一个状态。定义在特定状态下收到特定事件后,应跳转到哪个新状态的规则表,是状态机的核心约束。 |
PENDING → RUNNING(合法),SUCCEEDED → RUNNING(非法,直接拒绝) |
关键特性:状态机只允许合法的状态跃迁。例如,一个已经 成功 的节点,无论收到什么事件或满足什么条件,都不能再变为 运行中。这从根本上杜绝了状态混乱。
1.2.2 什么是变量池?
变量池(VariablePool)是工作流引擎中用于跨节点共享数据的全局上下文容器,本质上是一个命名空间隔离的键值存储。
命名空间 (Namespace):每个节点拥有独立的命名空间(以 node_id 区分),节点只能写入自己命名空间下的变量,有效防止命名冲突。变量选择器 (Variable Selector):下游节点通过 [上游节点ID, 变量名] 的路径精确读取特定节点的输出,实现声明式的跨节点数据引用。线程安全:内部通过锁机制保护并发读写,确保多个节点并行执行时数据不会互相干扰。
1.2.3 常见应用场景
| 场景 |
状态机的应用 |
变量池的应用 |
| 工作流引擎 |
管理每个节点(任务)的生命周期状态 |
节点间传递中间结果(如 LLM 输出、检索文档) |
| 电商订单系统 |
订单从待支付→已支付→已发货→已完成的状态流转 |
存储订单上下文(用户信息、商品列表、支付结果) |
| 游戏 AI |
角色在巡逻、追击、攻击、逃跑等行为间切换 |
共享游戏世界状态(地图、玩家位置、技能冷却) |
| 网络协议(TCP) |
连接在 CLOSED→SYN_SENT→ESTABLISHED→FIN_WAIT 间流转 |
共享连接上下文(序列号、窗口大小、对端地址) |
| CI/CD 流水线 |
Job 在 Queued→Running→Passed/Failed 间转换 |
构建产物、环境变量在各阶段间传递 |
1.2.4 场景示例:智能客服工单处理
假设我们要构建一个 AI 客服系统,处理一条用户工单的完整流程:
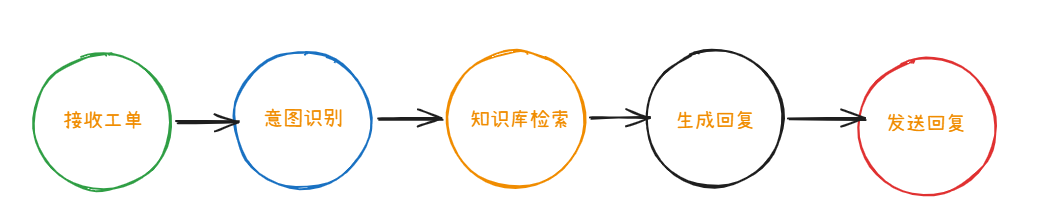
变量池视角(数据纬度):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| pool = {
"start_node": {
"ticket_content": "我的订单一直显示运输中,已经7天了",
"user_id": "U_12345",
},
"intent_node": {
"intent": "物流查询",
"confidence": 0.95,
},
"retrieval_node": {
"documents": ["物流超时处理流程:...", "客服话术模板:..."],
},
"llm_node": {
"reply": "您好,非常抱歉给您带来不便。根据您的订单情况...",
}
}
|
两个视角各司其职,共同支撑了整个工单处理流程的有序、安全运行。
1.3 状态机与上下文传递是如何协同的?(核心原理)
1.3.1 协同工作流程图解
- 查找入度为0节点 → 状态机.transit(PENDING→RUNNING) → 线程池执行节点
- 节点执行前:变量池.get([上游节点ID, 变量名]) → 解析输入 → 节点执行中:业务逻辑运行 → 节点执行后:变量池.set(当前节点ID, 变量名, 输出值)
- 成功路径:状态机.transit(RUNNING→SUCCEEDED)
- 失败路径:状态机.transit(RUNNING→FAILED)
- 触发下游:减少下游节点入度,归零则 transit(PENDING→RUNNING)
1.3.2 详细步骤说明
状态初始化 (State Initialization)
事件触发与状态转换 (Event-driven State Transition)
调度器找到所有入度为 0 的节点,向状态机发出 START 事件
状态机校验转换合法性(PENDING → RUNNING),通过后更新状态,记录 started_at 时间戳
节点执行完毕后,根据执行结果触发 SUCCEED 或 FAIL 事件,状态机再次校验并更新至终态
1
2
3
4
5
6
7
8
9
10
| 合法的状态转换矩阵:
┌────────────┬─────────────────────────────────────┐
│ 当前状态 │ 允许跃迁到 │
├────────────┼─────────────────────────────────────┤
│ PENDING │ RUNNING, SKIPPED │
│ RUNNING │ SUCCEEDED, FAILED │
│ SUCCEEDED │ (终态,不允许任何跃迁) │
│ FAILED │ (终态,不允许任何跃迁) │
│ SKIPPED │ (终态,不允许任何跃迁) │
└────────────┴─────────────────────────────────────┘
|
上下文读取:变量解析 (Variable Resolution)
节点执行前,引擎读取该节点的输入配置(通常为模板字符串或变量选择器)
VariableResolver(变量解析器)遍历配置,将所有 {{ node_id.key }} 形式的引用替换为变量池中的实际值
关键保证:由于状态机确保上游节点 SUCCEEDED 后才触发下游,此时读取上游变量一定有值
1
2
3
4
5
6
7
| 输入配置(模板):
prompt = "用户问题:{{ start_node.ticket_content }}
参考文档:{{ retrieval_node.documents }}"
解析后(实际执行时):
prompt = "用户问题:我的订单一直显示运输中,已经7天了
参考文档:['物流超时处理流程:...', '客服话术模板:...']"
|
上下文写入:结果存储 (Result Storage)
1.4 状态机与变量池在 Dify 中的核心价值
总结来说,状态机与变量池系统在真实的业务工程中,主要发挥三个维度的作用:
- 精确驱动节点全生命周期:避免产生不可预期的节点行为。
- 实现节点间数据无缝流转:通过变量池解耦,实现声明式的跨节点数据引用。
- 保障并发安全与全链路可追溯:解决多节点并行时的冲突机制并实现工作流状态恢复。
那么在真正的商业级大模型应用(Dify)中,这套系统是如何运转的?接下来,我们将深入源码进行探讨。
二、Dify 的代码实现
本章我们将深入 Dify 源码,看上述理论是如何转化为代码的。
2.1 贯穿案例:智能客服工单流转
为了不让大家迷失在抽象的源码中,我们还是以 AI 客服系统 举例。
我们将以当“知识库检索 节点完成了检索,将要流转到 LLM 节点”这一瞬间为切入点,看看底层的核心类是如何交互完成读取数据、更新状态、广播事件的。在这一过程中,我们需要实现:
- 数据的载体:不同节点的输出如何存储在各自的命名空间下?按什么规则取?
- 规则的约束:状态跃迁如何被安全控制?
- 运转的引擎:事件一来,系统是如何配合运转的?
接下来,我们按照工作流节点的“执行生命周期”循序渐进地解析源码。
2.2 关键源码详解
2.2 关键源码详解:按执行生命周期解析
2.2.1 数据的载体:VariablePool 与 VariableResolver
在执行大模型节点(LLM)前,不仅要获取用户意图,还需要拼接之前 Retrieval 节点吐出的上下文文档。这时就需要下面这两个类登场:
1. VariablePool
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
| from threading import Lock
from typing import Any, Optional
class VariablePool:
"""
变量池 - 工作流全局上下文容器
设计要点:
1. 命名空间隔离:每个变量由 (namespace, key) 二元组唯一标识
- 系统内置命名空间:'sys'(系统变量)、'env'(环境变量)、'session'(会话变量)
- 节点输出命名空间:以 node_id 为 namespace,节点执行后写入
2. 线程安全:写操作(set)通过锁保护;读操作在写锁释放后进行
3. 不可变原则:已写入的变量值不允许覆盖(同一节点同一变量名只能写一次)
防止重试或并发导致的数据错乱
"""
def __init__(
self,
user_inputs: dict[str, Any],
system_variables: dict[str, Any],
environment_variables: dict[str, Any],
session_variables: dict[str, Any],
) -> None:
self._lock = Lock()
self._pool: dict[str, dict[str, Any]] = {
"sys": system_variables,
"env": environment_variables,
"session": session_variables,
"user": user_inputs,
}
def set(self, node_id: str, key: str, value: Any) -> None:
"""
写入节点输出变量
- 以 node_id 作为命名空间,确保不同节点的输出互不干扰
- 幂等保护:已存在的变量不允许覆盖,防止重试场景下的数据污染
"""
with self._lock:
if node_id not in self._pool:
self._pool[node_id] = {}
if key in self._pool[node_id]:
return
self._pool[node_id][key] = value
def get(self, variable_selector: list[str]) -> Optional[Any]:
"""
读取变量
variable_selector: 变量路径,格式为 [namespace, key]
例如:
["user", "query"] → 用户输入的 query 字段
["sys", "workflow_run_id"] → 系统变量
["llm_node_1", "output"] → llm_node_1 节点的 output 输出
读操作不需要加锁(Python GIL 保证基本读操作原子性),
但为了保障强一致性语义,此处仍加锁
"""
if len(variable_selector) < 2:
raise ValueError(f"变量选择器格式错误: {variable_selector},至少需要 [namespace, key]")
namespace = variable_selector[0]
key = variable_selector[1]
with self._lock:
namespace_dict = self._pool.get(namespace)
if namespace_dict is None:
return None
return namespace_dict.get(key)
def get_or_raise(self, variable_selector: list[str]) -> Any:
"""读取变量,不存在则抛出异常(用于必填输入的校验)"""
value = self.get(variable_selector)
if value is None:
raise KeyError(
f"变量 {variable_selector} 在变量池中不存在。"
f"请检查上游节点是否已成功执行,或变量名是否正确。"
)
return value
def has(self, variable_selector: list[str]) -> bool:
"""检查变量是否存在"""
return self.get(variable_selector) is not None
|
传统的做法是直接在代码中强耦合传参 llm_run(docs=retrieval_output),但在 Dify 中,依靠 VariableResolver 使用动态路径读取(例如路径:['retrieval_node', 'docs']),有效解耦:
2. VariableResolver
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
| import re
from typing import Any
class VariableResolver:
"""
变量解析器 - 负责将节点配置中的变量引用替换为实际值
支持两种引用方式:
1. 模板语法(用于字符串拼接):{{ node_id.key }}
例如:"请基于以下内容回答:{{ retrieval_node.documents }}"
2. 变量选择器(用于直接传值):["node_id", "key"]
例如:inputs["query"] = ["start_node", "user_query"]
→ inputs["query"] = "用户实际输入的问题"
"""
TEMPLATE_PATTERN = re.compile(r'\{\{\s*([\w]+\.[\w.]+)\s*\}\}')
def __init__(self, variable_pool: VariablePool) -> None:
self._pool = variable_pool
def resolve_template(self, template: str) -> str:
"""
解析模板字符串,将所有 {{ namespace.key }} 替换为实际值
示例:
template = "用户问:{{ user.query }},参考:{{ retrieval_node.context }}"
→ "用户问:什么是DAG?,参考:DAG是有向无环图..."
"""
def replace_match(match: re.Match) -> str:
parts = match.group(1).split('.')
value = self._pool.get(parts)
if value is None:
raise KeyError(
f"模板变量 '{{{{ {match.group(1)} }}}}' 无法解析:变量不存在于变量池中。"
f"请确认上游节点已成功执行且输出了该变量。"
)
if isinstance(value, (list, dict)):
return str(value)
return str(value)
return self.TEMPLATE_PATTERN.sub(replace_match, template)
def resolve_selector(self, selector: list[str]) -> Any:
"""
解析变量选择器,返回实际值
selector: ["namespace", "key"],如 ["llm_node", "reply"]
"""
return self._pool.get_or_raise(selector)
def resolve_node_inputs(self, input_config: dict[str, Any]) -> dict[str, Any]:
"""
批量解析节点的所有输入配置
- 字符串类型的值:尝试作为模板解析
- 列表类型的值(变量选择器格式):直接解析为实际值
- 其他类型:原样传递
示例:
input_config = {
"prompt": "请基于{{ retrieval_node.documents }}回答{{ user.query }}",
"max_tokens": 512,
"context": ["retrieval_node", "documents"],
}
→ resolved = {
"prompt": "请基于[检索到的文档...]回答什么是DAG?",
"max_tokens": 512,
"context": ["DAG是有向无环图...", "Kahn算法用于拓扑排序..."],
}
"""
resolved: dict[str, Any] = {}
for key, value in input_config.items():
if isinstance(value, str):
resolved[key] = self.resolve_template(value)
elif (isinstance(value, list)
and len(value) == 2
and all(isinstance(v, str) for v in value)):
resolved[key] = self.resolve_selector(value)
elif isinstance(value, dict):
resolved[key] = self.resolve_node_inputs(value)
else:
resolved[key] = value
return resolved
|
2.2.2 规则的约束:NodeRunStatus 与 GraphRuntimeState
当数据准备好后,调度器准备启动节点。但它必须严格遵循状态跃迁法则:
1. NodeRunStatus
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| from enum import Enum
from typing import Set
class NodeRunStatus(str, Enum):
"""
节点运行状态枚举 - 状态机的"状态"定义
继承 str 使其可以直接序列化为 JSON,便于持久化存储
"""
PENDING = "pending"
RUNNING = "running"
SUCCEEDED = "succeeded"
FAILED = "failed"
SKIPPED = "skipped"
VALID_TRANSITIONS: dict[NodeRunStatus, Set[NodeRunStatus]] = {
NodeRunStatus.PENDING: {
NodeRunStatus.RUNNING,
NodeRunStatus.SKIPPED,
},
NodeRunStatus.RUNNING: {
NodeRunStatus.SUCCEEDED,
NodeRunStatus.FAILED,
},
NodeRunStatus.SUCCEEDED: set(),
NodeRunStatus.FAILED: set(),
NodeRunStatus.SKIPPED: set(),
}
|
2. NodeExecutionStats
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| import time
from dataclasses import dataclass, field
from typing import Any, Optional
@dataclass
class NodeExecutionStats:
"""
单个节点的运行时统计信息 - 节点状态机的"数据载体"
记录节点从 PENDING 到终态的完整执行轨迹,包括:
- 状态(State):当前处于哪个生命周期阶段
- 时间戳(Timestamps):各阶段的精确时间,用于性能分析
- 数据快照(Snapshots):输入/输出的完整记录,用于问题追溯
"""
node_id: str
node_type: str
status: NodeRunStatus = NodeRunStatus.PENDING
started_at: Optional[float] = None
finished_at: Optional[float] = None
inputs: dict[str, Any] = field(default_factory=dict)
outputs: dict[str, Any] = field(default_factory=dict)
error: Optional[str] = None
error_detail: Optional[str] = None
@property
def elapsed_time(self) -> Optional[float]:
"""节点执行耗时(秒),仅在终态时有值"""
if self.started_at and self.finished_at:
return self.finished_at - self.started_at
return None
@property
def is_terminal(self) -> bool:
"""是否处于终态(Succeeded / Failed / Skipped)"""
return self.status in (
NodeRunStatus.SUCCEEDED,
NodeRunStatus.FAILED,
NodeRunStatus.SKIPPED,
)
|
3. GraphRuntimeState
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
| import time
from threading import Lock
from typing import Optional
class GraphRuntimeState:
"""
图运行时状态 - 工作流执行的"总控台"
职责:
- 集中管理所有节点的执行状态(状态机入口)
- 持有变量池的引用(上下文传递的入口)
- 记录全局执行统计(可观测性)
- 所有操作线程安全,支持多节点并行执行
"""
def __init__(self, variable_pool: "VariablePool") -> None:
self.variable_pool = variable_pool
self._node_stats: dict[str, NodeExecutionStats] = {}
self._lock = Lock()
self.total_steps: int = 0
self.started_at: float = time.time()
def initialize_node(self, node_id: str, node_type: str) -> None:
"""
初始化节点状态为 PENDING
在 DAG 图构建完成后、执行开始前调用,为所有节点预建状态槽位
"""
with self._lock:
self._node_stats[node_id] = NodeExecutionStats(
node_id=node_id,
node_type=node_type,
status=NodeRunStatus.PENDING,
)
def transit(
self,
node_id: str,
new_status: NodeRunStatus,
*,
inputs: Optional[dict] = None,
outputs: Optional[dict] = None,
error: Optional[str] = None,
error_detail: Optional[str] = None,
) -> NodeExecutionStats:
"""
节点状态转换 - 状态机的核心方法
严格校验转换合法性:
- 非法跃迁(如 SUCCEEDED → RUNNING)直接抛出异常,绝不静默放行
- 合法跃迁自动更新时间戳、数据快照,并维护全局计数器
并发安全:整个"校验 + 写入"过程在同一个锁范围内原子完成
"""
with self._lock:
stats = self._node_stats.get(node_id)
if stats is None:
raise ValueError(f"节点 '{node_id}' 未初始化,请先调用 initialize_node()")
current_status = stats.status
allowed = VALID_TRANSITIONS.get(current_status, set())
if new_status not in allowed:
raise InvalidStateTransitionError(
f"节点 '{node_id}': 非法状态跃迁 {current_status} → {new_status},"
f"当前状态允许跃迁到: {allowed}"
)
stats.status = new_status
if new_status == NodeRunStatus.RUNNING:
stats.started_at = time.time()
self.total_steps += 1
if inputs is not None:
stats.inputs = inputs
elif new_status in (NodeRunStatus.SUCCEEDED, NodeRunStatus.FAILED, NodeRunStatus.SKIPPED):
stats.finished_at = time.time()
if outputs is not None:
stats.outputs = outputs
if error is not None:
stats.error = error
if error_detail is not None:
stats.error_detail = error_detail
return stats
def get_node_status(self, node_id: str) -> Optional[NodeRunStatus]:
"""线程安全地查询节点当前状态"""
with self._lock:
stats = self._node_stats.get(node_id)
return stats.status if stats else None
def get_all_stats(self) -> dict[str, NodeExecutionStats]:
"""获取所有节点统计快照(浅拷贝),用于日志或持久化"""
with self._lock:
return dict(self._node_stats)
class InvalidStateTransitionError(Exception):
"""非法状态跃迁异常 - 表明引擎内部逻辑出现了严重错误"""
pass
|
2.2.3 运转的引擎:WorkflowEvent
当 LLM 节点执行成功并存储数据后,事件系统会广播成功信号,调度器放行后续节点。
1. WorkflowEvent
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| from abc import ABC
from dataclasses import dataclass, field
from typing import Any, Optional
import time
class WorkflowEvent(ABC):
"""
工作流事件基类 - 事件驱动架构的基础
作用:将引擎内部的状态变更解耦地广播给外部观察者:
- 数据库持久化层:将事件写入数据库,支持断点续跑
- WebSocket 推送层:将事件实时推送给前端,驱动可视化进度更新
- 日志系统:将事件写入日志,支持离线分析
- 监控告警:特定事件(如 NodeFailedEvent)触发告警通知
设计原则:外部观察者只需消费事件流,无需了解引擎内部逻辑
"""
pass
@dataclass
class NodeStartedEvent(WorkflowEvent):
"""节点开始执行事件(状态 PENDING → RUNNING 时触发)"""
node_id: str
node_type: str
inputs: dict[str, Any]
started_at: float = field(default_factory=time.time)
@dataclass
class NodeSucceededEvent(WorkflowEvent):
"""节点执行成功事件(状态 RUNNING → SUCCEEDED 时触发)"""
node_id: str
node_type: str
outputs: dict[str, Any]
elapsed_time: float
finished_at: float = field(default_factory=time.time)
@dataclass
class NodeFailedEvent(WorkflowEvent):
"""节点执行失败事件(状态 RUNNING → FAILED 时触发)"""
node_id: str
node_type: str
error: str
error_detail: Optional[str]
elapsed_time: float
finished_at: float = field(default_factory=time.time)
@dataclass
class NodeSkippedEvent(WorkflowEvent):
"""节点跳过事件(状态 PENDING → SKIPPED 时触发)"""
node_id: str
node_type: str
reason: str
@dataclass
class WorkflowStartedEvent(WorkflowEvent):
"""工作流开始执行事件"""
workflow_run_id: str
started_at: float = field(default_factory=time.time)
@dataclass
class WorkflowCompletedEvent(WorkflowEvent):
"""工作流执行完成事件(所有节点终态)"""
workflow_run_id: str
outputs: dict[str, Any]
total_steps: int
elapsed_time: float
finished_at: float = field(default_factory=time.time)
@dataclass
class WorkflowFailedEvent(WorkflowEvent):
"""工作流执行失败事件(任一关键节点失败且无错误处理分支)"""
workflow_run_id: str
error: str
finished_at: float = field(default_factory=time.time)
|
三、 常见问题与解决方案
在 Dify 的实际开发和运行中,状态机与变量池机制遇到了哪些典型问题?又是如何解决的?