基于Dify认识工作流引擎:DAG调度
一、从痛点到原理
1.1 开发工作中的痛点
在日常业务开发和系统运维中,我们经常面临以下严峻挑战:
- 多任务依赖混乱:
场景:一个数据处理任务需要等待 A、B、C 三个上游任务完成后才能启动,而 D 任务只需要 A 完成即可。痛点:手动维护这种复杂的依赖关系(如通过 Cron 脚本轮询状态)极易出错,一旦某个环节延迟,整个链路阻塞且难以感知。
- 调度低效:
场景:传统线性执行模式(串行)导致资源闲置。例如,任务 B 不依赖任务 A,但必须等 A 跑完才启动。痛点:无法充分利用集群算力,整体耗时 = 所有任务耗时之和,效率低下。
- 流程不可控:
场景:任务执行中途失败,是重试?跳过?还是回滚?缺乏统一的策略。痛点:错误处理逻辑硬编码在业务代码中,耦合严重,难以动态调整。
- 可追溯性差:
场景:最终结果异常,需要排查是哪个环节、哪次输入导致了问题。痛点:缺乏完整的执行链路记录(Input/Output/Status),问题排查如“大海捞针”。
结论:我们需要一种能够自动管理依赖、最大化并发、统一容错且全程可观测的调度机制。这就是 DAG(有向无环图)调度 诞生的背景。
1.2 什么是 DAG?
在深入代码之前,我们先回顾一下DAG基础理论。
1.2.1 定义
DAG (Directed Acyclic Graph),即有向无环图。
有向 (Directed):边有方向,代表任务执行的先后顺序(A → B 表示 A 必须在 B 之前)。无环 (Acyclic):图中不存在回路,即不可能从一个节点出发沿着箭头方向又能回到该节点(避免死循环)。图 (Graph):由节点 (Node) 和 边 (Edge) 组成的数据结构。
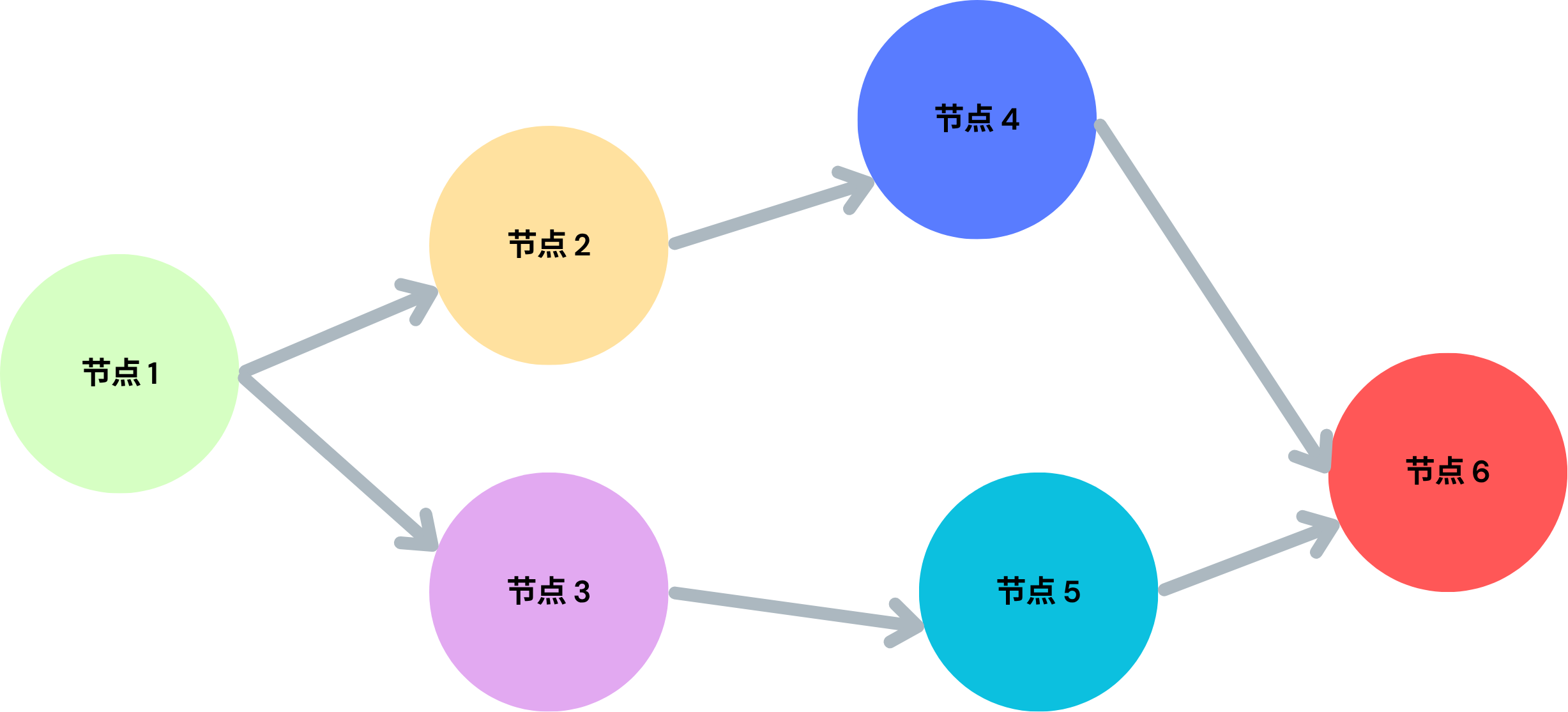
加权 DAG: 在实际工程和算法问题中,有时边带有权重,用来表示某种“代价”或“量化关系”。

1.2.2 核心三要素
| 要素 | 含义 | 业务映射 |
|---|---|---|
节点 (Node) |
图中的基本单元 | 一个具体的任务(如:调用 LLM、执行 Python 代码、发送 HTTP 请求) |
边 (Edge) |
连接节点的有向线段 | 任务间的依赖关系(前置任务完成 -> 触发后置任务) |
无环性 |
图中不存在闭环 | 保证流程必然能结束,不会出现“A 等 B,B 等 A”的死锁 |
1.2.3 常见的应用场景
| 场景 | 是否有权重 | 权重的含义 | 典型应用 |
|---|---|---|---|
| 任务调度/依赖关系 | 通常没有 | 仅表示 A 必须在 B 之前完成 | 工作流引擎、CI/CD 流水线、构建系统 |
| 最短/最长路径算法 | 有 | 表示距离、耗时、成本或利润 | 导航系统、网络路由、关键路径分析 |
| 动态规划(DP) | 有 | 状态转移的代价或收益 | 最优子结构问题、背包问题、编辑距离 |
| 神经网络(计算图) | 有 | 在深度学习中,边权重通常代表神经元之间的连接权重 | 深度学习框架(TensorFlow、PyTorch)、模型训练 |
| 分布式事务 | 通常没有 | 表示事务操作的先后顺序和依赖 | 两阶段提交(2PC)、Saga 模式 |
1.2.4 场景示例:视频转码流水线
假设我们要对一个视频进行处理:
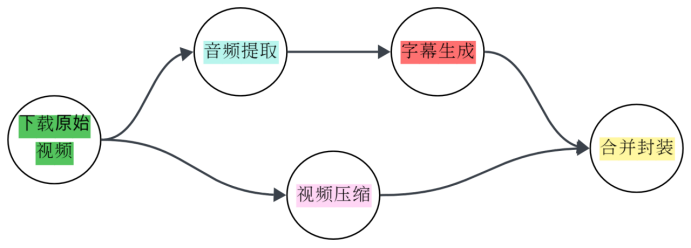
- 并行性:
音频提取和视频压缩互不依赖,可以同时执行。 - 依赖性:合并输出 必须等待
字幕生成和视频压缩都完成后才能开始。 - 无环性:流程单向流动,绝不会从
合并封装跳回下载原始视频。
1.3 DAG 是如何调度的?(核心原理)
理解了结构,DAG 引擎是如何驱动这些任务运行的?核心流程分为四步:
1.3.1 调度流程图解

1.3.2 详细步骤说明
解析与构建 (Parse & Build)
读取配置文件(JSON/YAML),提取所有的节点定义和边关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47# 视频处理 DAG 工作流配置
workflow:
name: "视频转码流水线"
version: "1.0"
# 节点定义
nodes:
- id: download_video
name: "下载原始视频"
type: "http_request"
config:
url: "{{ input.video_url }}"
method: "GET"
output: "raw_video_path"
- id: extract_audio
name: "音频提取"
type: "shell_command"
config:
command: "ffmpeg -i {{ download_video.raw_video_path }} -vn audio.mp3"
depends_on: ["download_video"]
output: "audio_path"
- id: compress_video
name: "视频压缩"
type: "shell_command"
config:
command: "ffmpeg -i {{ download_video.raw_video_path }} -vcodec libx264 compressed.mp4"
depends_on: ["download_video"]
output: "compressed_video_path"
- id: generate_subtitles
name: "字幕生成"
type: "ai_service"
config:
api: "whisper"
input: "{{ extract_audio.audio_path }}"
depends_on: ["extract_audio"]
output: "subtitle_path"
- id: merge_output
name: "合并封装"
type: "shell_command"
config:
command: "ffmpeg -i {{ compress_video.compressed_video_path }} -i {{ generate_subtitles.subtitle_path }} -c copy final_output.mp4"
depends_on: ["compress_video", "generate_subtitles"]
output: "final_video_path"在内存中构建图数据结构(邻接表或邻接矩阵)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38# 节点索引映射(用于矩阵定位)
node_index = {
"download_video": 0,
"extract_audio": 1,
"compress_video": 2,
"generate_subtitles": 3,
"merge_output": 4
}
# 邻接矩阵表示法 (Adjacency Matrix)
# matrix[i][j] = 1 表示节点 i 指向节点 j,否则为 0
adjacency_matrix = [
# dv ea cv gs mo
[0, 1, 1, 0, 0], # download_video (0)
[0, 0, 0, 1, 0], # extract_audio (1)
[0, 0, 0, 0, 1], # compress_video (2)
[0, 0, 0, 0, 1], # generate_subtitles (3)
[0, 0, 0, 0, 0] # merge_output (4)
]
# 邻接表表示法 (Adjacency List) - 更节省空间
# Key: 节点ID, Value: 该节点指向的所有后继节点列表
adjacency_list = {
"download_video": ["extract_audio", "compress_video"],
"extract_audio": ["generate_subtitles"],
"compress_video": ["merge_output"],
"generate_subtitles": ["merge_output"],
"merge_output": [] # 汇点,没有后继节点
}
# 反向邻接表(用于快速查找前置依赖)
reverse_adjacency_list = {
"download_video": [], # 源点,没有前置节点
"extract_audio": ["download_video"],
"compress_video": ["download_video"],
"generate_subtitles": ["extract_audio"],
"merge_output": ["compress_video", "generate_subtitles"]
}选择建议:
- DAG 工作流通常是稀疏图(每个节点只有少量依赖),推荐使用邻接表
- 邻接矩阵适合需要频繁判断”任意两节点是否有边”的场景
- 实际工程中(如 Dify),多采用邻接表 + 哈希表的组合方案
关键点:此时只建立结构,不执行任何业务逻辑
拓扑排序 (Topological Sort)
目的:确定一个合法的线性执行序列,或者验证图的合法性
算法:通常使用
Kahn 算法或DFS核心逻辑:
1
2
3
4
5
6
7
8# 入度统计(用于拓扑排序)
in_degree = {
"download_video": 0,
"extract_audio": 1,
"compress_video": 1,
"generate_subtitles": 1,
"merge_output": 2
}- 统计每个节点的入度(有多少个前置任务)
- 将入度为 0 的节点加入队列
- 依次处理队列中的节点,将其后继节点的入度减 1,若减后入度为 0 则加入队列
- 如果最终处理的节点数等于总节点数,则无环;否则存在循环依赖,报错终止
- 作用:提前发现配置错误,避免运行时死锁
就绪检测 (Ready Check)
- 在运行时,引擎维护一个运行时状态表
- 当一个节点执行成功后,将其所有下游节点的”已完成前置计数”减 1
- 当某节点的”已完成前置计数”归零时,标记为
Ready(就绪)
并发执行 (Execution)
- 调度器不断扫描
Ready队列 - 将 Ready 节点提交给线程池或协程池异步执行
- 优势:互不依赖的分支天然并行,最大化利用资源
- 状态流转:
Running→Success/Fail→ 触发下游/报错
- 调度器不断扫描
1.4 从理论到落地:以 Dify 为例解析 DAG 实践
理解了 DAG 的理论价值后,我们需要一个成熟的工程化案例来观察它是如何落地的。Dify 工作流引擎是业界基于 DAG 理论构建的典型代表,其内部完整实现了依赖管理、拓扑排序和并发调度机制。
本次分享将以 Dify 的源码实现为蓝本,深入剖析:
- 理论映射:DAG 的抽象概念(节点、边、状态)在代码中如何具体定义。
- 调度实战:拓扑排序算法如何在真实的高并发场景中被调用和执行。
- 工程挑战:面对失败重试、断点续跑等复杂需求,DAG 引擎是如何扩展和解决的。
通过拆解 Dify 这个”标本”,我们不仅能掌握 DAG 调度的通用原理,更能获得一套可复用的架构设计思路,应用于公司未来的各类任务编排场景中。
二、DAG 调度的核心作用
承接第一章的原理,DAG 调度在实际业务中具体解决了哪些核心问题?
2.1 支撑复杂自动化任务流转
在 Dify 中,工作流不仅仅是简单的线性脚本,而是支持复杂逻辑的编排系统。它定义了多种节点类型来覆盖不同场景:
| 节点类型 | 英文标识 | 作用 | 典型场景 |
|---|---|---|---|
| 开始节点 | START | 流程入口,接收初始参数 | API 触发、定时任务触发 |
| 大模型节点 | LLM | 调用 LLM 进行推理 | 文本生成、意图识别、润色 |
| HTTP 请求 | HTTP_REQUEST | 调用外部 API | 查询天气、调用内部微服务 |
| 代码执行 | CODE | 运行 Python/JS 片段 | 数据清洗、格式转换、复杂计算 |
| 模板转换 | TEMPLATE_TRANSFORM | 字符串模板渲染 | 构造 Prompt、格式化输出 |
| 知识检索 | KNOWLEDGE_RETRIEVAL | 向量数据库查询 | RAG 场景下的上下文获取 |
| 工具调用 | TOOL | 调用预定义插件 | 搜索谷歌、执行 SQL、画图 |
| 结束节点 | END | 流程终点,输出最终结果 | 返回给用户响应 |
实际场景示例:智能客服工单处理
DAG 调度确保了:
- 检索和日志记录可以并行。
- 意图判断完成后,根据结果动态选择分支。
- 所有分支最终汇聚到 END 节点,保证流程完整性。
2.2 解决多模块协同依赖
在传统脚本中,模块间调用往往是硬编码的(func_a(); func_b())。而在 DAG 中,依赖是通过元数据描述的:
- 解耦:节点 A 不需要知道节点 B 的存在,它只负责执行自己的逻辑并通知引擎“我完成了”。
- 自动触发:引擎通过维护 GraphRuntimeState(运行时状态),自动计算哪些节点的所有上游已完成。
- 数据传递:通过 VariablePool(变量池),上游节点的输出自动映射为下游节点的输入,无需手动传参。
核心价值:新增一个中间处理环节,只需在配置图中插入一个节点并连线,无需修改任何现有业务代码。
2.3 提升稳定性和可追溯性
Dify 基于 DAG 架构,内置了企业级的稳定性保障:
- 状态持久化:
每一步执行状态(Running/Success/Failed)都实时写入数据库 (WorkflowRunRepository)。
即使服务器重启,也能从断点恢复(取决于具体实现策略)。 - 精细化失败重试:
支持针对特定节点配置重试策略(如:网络波动导致的 HTTP 失败重试 3 次)。
局部失败不影响独立分支的执行。 - 执行限制保护:
通过 ExecutionLimitsLayer 防止死循环或资源耗尽(如:最大执行步数限制、总超时时间限制)。 - 全链路可观测:
每个节点的 Input、Output、Elapsed Time、Error Message 均有详细记录。
提供可视化的执行轨迹,一键定位瓶颈或错误点。
三、Dify 的代码实现
本章我们将深入 Dify 源码(基于 graphon 引擎),看上述理论是如何转化为代码的。
3.1 核心目标
在代码层面,我们需要实现四个核心目标:
- 正确解析 DAG 结构:从 JSON 配置构建内存图。
- 保证执行顺序:严格遵守依赖约束,绝不违规执行。
- 高效并发:识别独立分支,利用多线程/协程并行处理。
- 状态一致:在并发环境下,确保变量池和运行状态的线程安全。
3.2 关键源码详解
3.2.1 图引擎:GraphEngine
1 | class GraphEngine: |
3.2.2 图引擎线程池:GraphEngineThreadPool
1 | class GraphEngineThreadPool(ThreadPoolExecutor): |