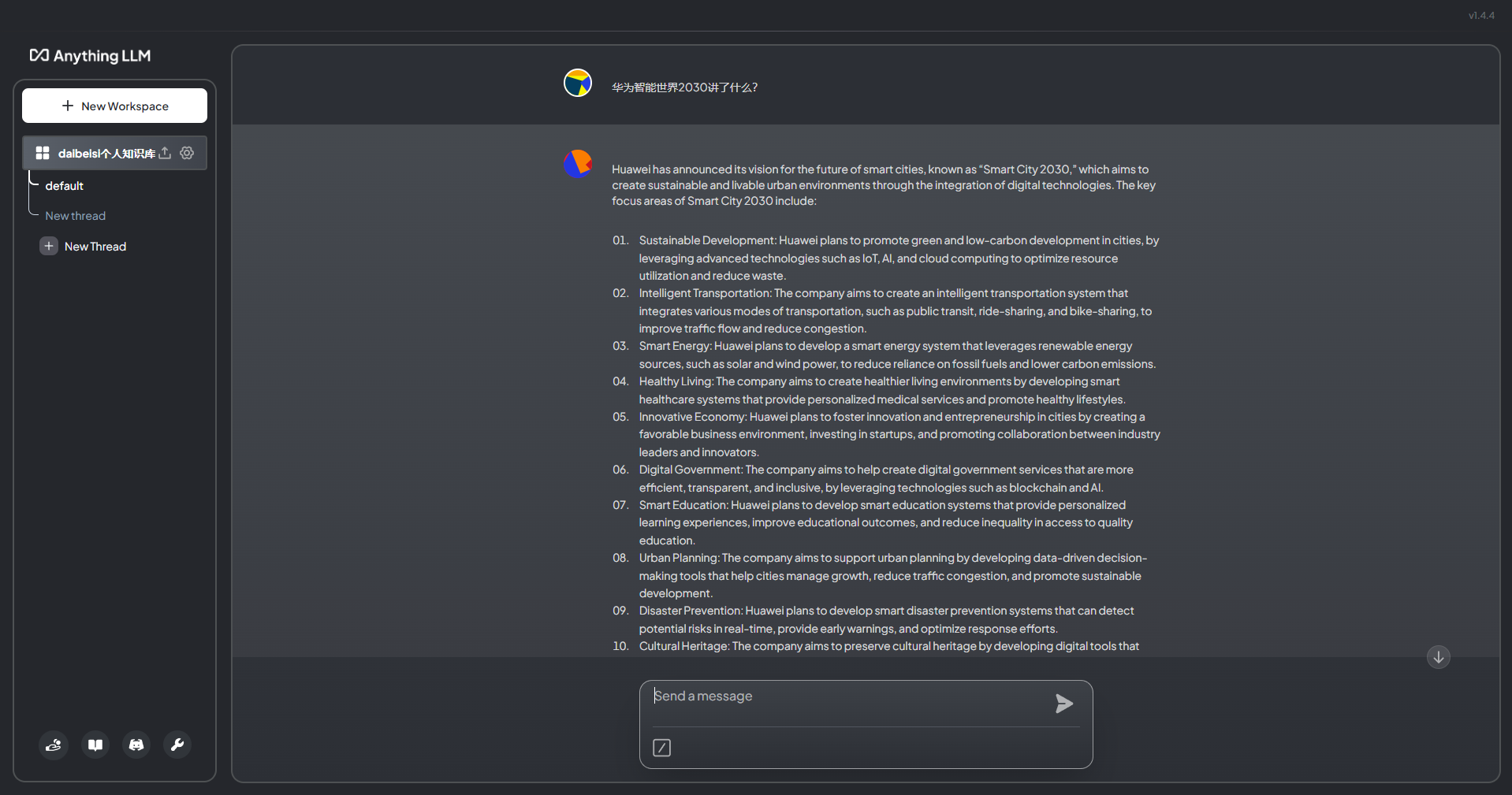
在进行本地知识库的搭建实操之前,我们需要先对RAG有一个大概的了解。
什么是 RAG 技术
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),
此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。 通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库,
检索增强生成能够提高搜索体验的相关性。这能够改善大型语言模型的输出,但又无需重新训练模型。
RAG 对于诸如回答问题和内容生成等任务,具有极大价值,因为它能支持生成式 AI 系统使用外部信息源生成更准确且更符合语境的回答。
它会实施搜索检索方法(通常是语义搜索或混合搜索)来回应用户的意图并提供更相关的结果。
我们可以将一个RAG的应用抽象为下图的5个过程:
- 文档加载(Document Loading) :从多种不同来源加载文档。LangChain提供了100多种不同的文档加载器,包括PDF在内的非结构化的数据、SQL在内的结构化的数据,以及Python、Java之类的代码等
- 文本分割(Splitting) :文本分割器把Documents 切分为指定大小的块,我把它们称为“文档块”或者“文档片”
- 存储(Storage): 存储涉及到两个环节,分别是: 将切分好的文档块进行嵌入(Embedding)转换成向量的形式 将Embedding后的向量数据存储到向量数据库
- 检索(Retrieval) :一旦数据进入向量数据库,我们仍然需要将数据检索出来,我们会通过某种检索算法找到与输入问题相似的嵌入片
- Output (输出) :把问题以及检索出来的嵌入片一起提交给LLM,LLM会通过问题和检索出来的提示一起来生成更加合理的答案
检索增强生成的工作原理是什么?
如果没有 RAG,LLM 会接受用户输入,并根据它所接受训练的信息或它已经知道的信息创建响应。RAG 引入了一个信息检索组件,
该组件利用用户输入首先从新数据源提取信息。用户查询和相关信息都提供给 LLM。LLM 使用新知识及其训练数据来创建更好的响应。以下各部分概述了该过程。
部署本地模型
启动 ollama
1
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
加载一个模型,这里以llama2为例
1
docker exec -itd ollama ollama run llama2
安装AnythingLLM
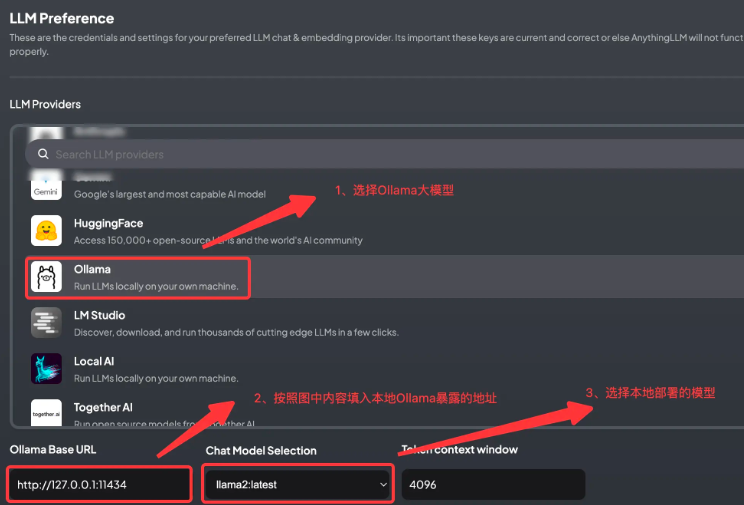
- 选择大模型
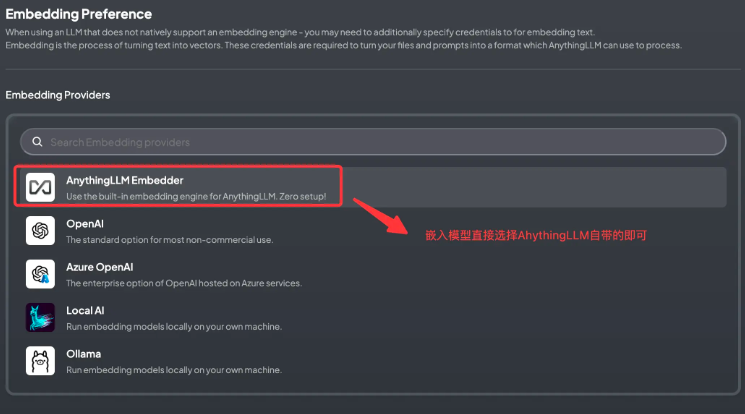
- 选择文本嵌入模型
- 选择向量数据库
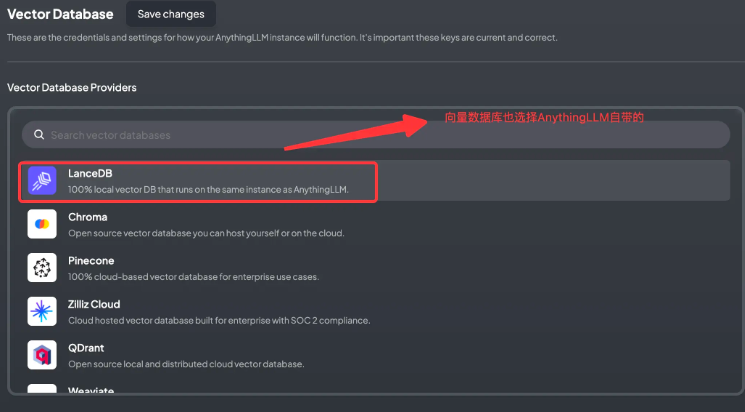
构建本地知识库
- 创建一个工作空间
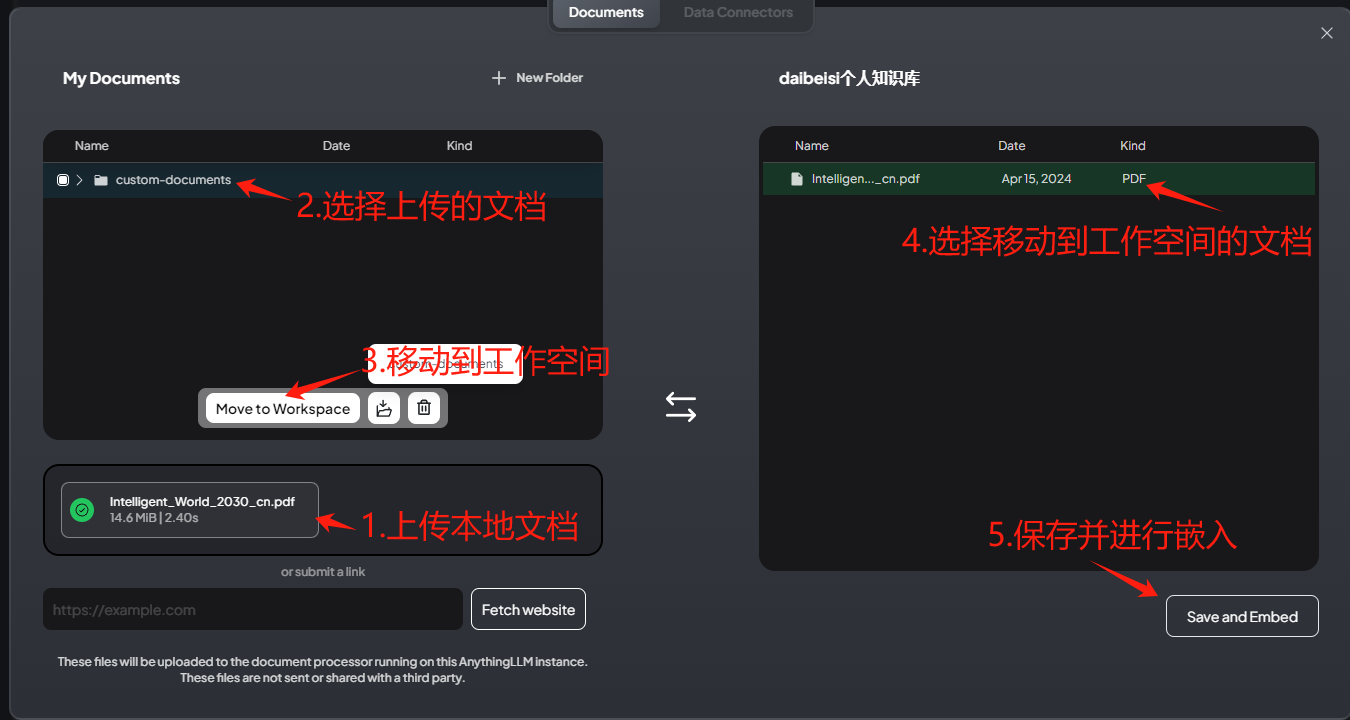
- 上传文档并且在工作空间中进行文本嵌入
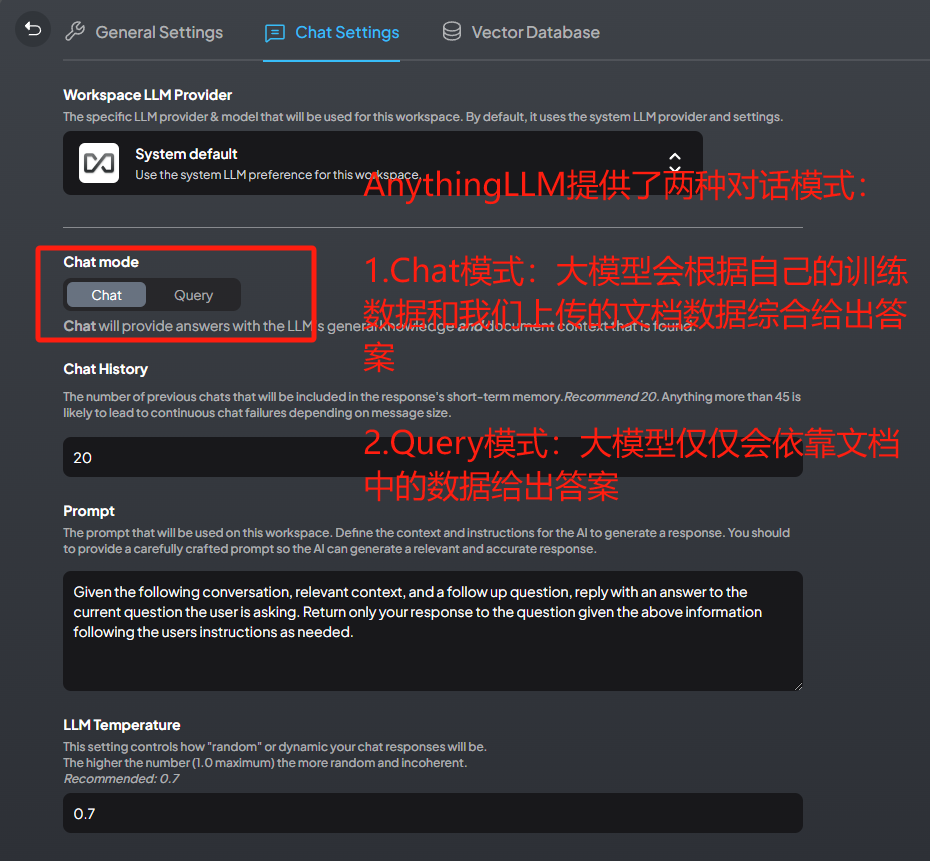
- 选择对话模式
- 测试对话