前提条件
- 一台Linux服务器
- 安装完docker
- 安装完Anaconda
安装Ollama
启动 ollama
1
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
加载一个模型,这里以llama2为例
1
docker exec -itd ollama ollama run llama2
安装Open WebUI
1 | docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
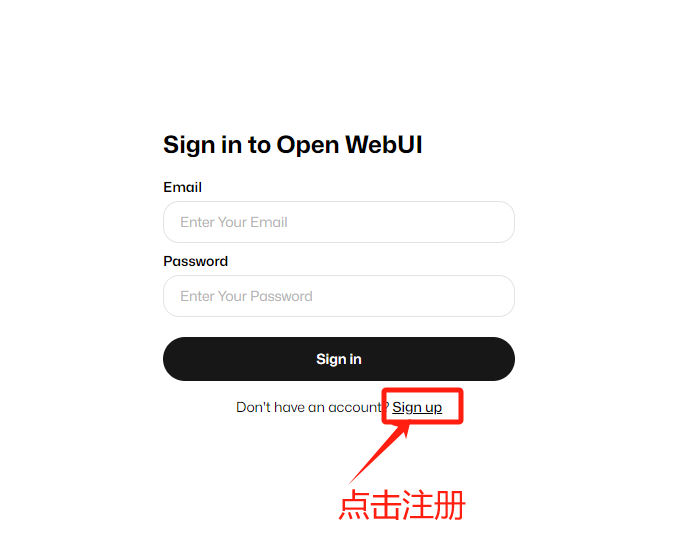
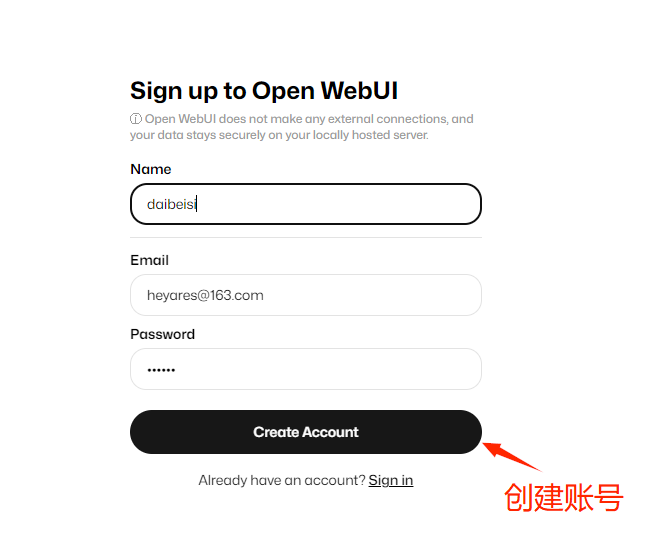
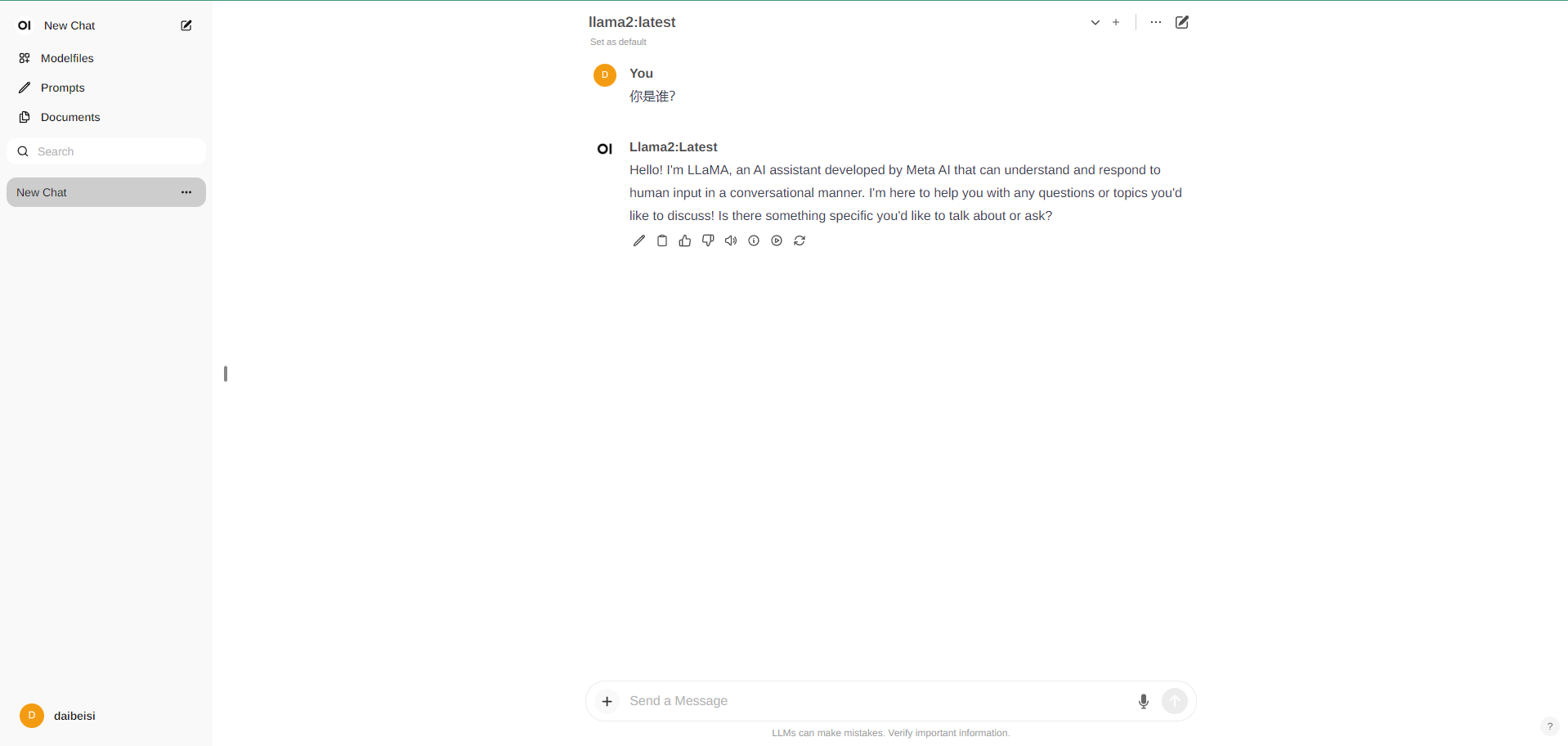
安装完成后访问服务器8080端口,点击注册登入即可使用。
提供API服务
ollama本身提供了API服务,但是流式处理有点问题,python版本的没问题,这里以一个api_demo为例对齐chatgpt的api。
安装依赖
1
pip install ollama sse_starlette fastapi
创建api_demo.py文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270import asyncio
import json
import os
from typing import Any, Dict, Sequence
import ollama
from sse_starlette.sse import EventSourceResponse
from fastapi import FastAPI, HTTPException, status
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
import time
from enum import Enum, unique
from typing import List, Optional
from pydantic import BaseModel, Field
from typing_extensions import Literal
class Role(str, Enum):
USER = "user"
ASSISTANT = "assistant"
SYSTEM = "system"
FUNCTION = "function"
TOOL = "tool"
OBSERVATION = "observation"
class Finish(str, Enum):
STOP = "stop"
LENGTH = "length"
TOOL = "tool_calls"
class ModelCard(BaseModel):
id: str
object: Literal["model"] = "model"
created: int = Field(default_factory=lambda: int(time.time()))
owned_by: Literal["owner"] = "owner"
class ModelList(BaseModel):
object: Literal["list"] = "list"
data: List[ModelCard] = []
class Function(BaseModel):
name: str
arguments: str
class FunctionCall(BaseModel):
id: Literal["call_default"] = "call_default"
type: Literal["function"] = "function"
function: Function
class ChatMessage(BaseModel):
role: Role
content: str
class ChatCompletionMessage(BaseModel):
role: Optional[Role] = None
content: Optional[str] = None
tool_calls: Optional[List[FunctionCall]] = None
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
tools: Optional[list] = []
do_sample: bool = True
temperature: Optional[float] = None
top_p: Optional[float] = None
n: int = 1
max_tokens: Optional[int] = None
stream: bool = False
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ChatCompletionMessage
finish_reason: Finish
class ChatCompletionResponseStreamChoice(BaseModel):
index: int
delta: ChatCompletionMessage
finish_reason: Optional[Finish] = None
class ChatCompletionResponseUsage(BaseModel):
prompt_tokens: int
completion_tokens: int
total_tokens: int
class ChatCompletionResponse(BaseModel):
id: Literal["chatcmpl-default"] = "chatcmpl-default"
object: Literal["chat.completion"] = "chat.completion"
created: int = Field(default_factory=lambda: int(time.time()))
model: str
choices: List[ChatCompletionResponseChoice]
usage: ChatCompletionResponseUsage
class ChatCompletionStreamResponse(BaseModel):
id: Literal["chatcmpl-default"] = "chatcmpl-default"
object: Literal["chat.completion.chunk"] = "chat.completion.chunk"
created: int = Field(default_factory=lambda: int(time.time()))
model: str
choices: List[ChatCompletionResponseStreamChoice]
class ScoreEvaluationRequest(BaseModel):
model: str
messages: List[str]
max_length: Optional[int] = None
class ScoreEvaluationResponse(BaseModel):
id: Literal["scoreeval-default"] = "scoreeval-default"
object: Literal["score.evaluation"] = "score.evaluation"
model: str
scores: List[float]
def dictify(data: "BaseModel") -> Dict[str, Any]:
try: # pydantic v2
return data.model_dump(exclude_unset=True)
except AttributeError: # pydantic v1
return data.dict(exclude_unset=True)
def jsonify(data: "BaseModel") -> str:
try: # pydantic v2
return json.dumps(data.model_dump(exclude_unset=True), ensure_ascii=False)
except AttributeError: # pydantic v1
return data.json(exclude_unset=True, ensure_ascii=False)
def create_app() -> "FastAPI":
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
semaphore = asyncio.Semaphore(int(os.environ.get("MAX_CONCURRENT", 1)))
async def list_models():
model_card = ModelCard(id="gpt-3.5-turbo")
return ModelList(data=[model_card])
async def create_chat_completion(request: ChatCompletionRequest):
if len(request.messages) == 0 or request.messages[-1].role not in [Role.USER, Role.TOOL]:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="Invalid length")
messages = [dictify(message) for message in request.messages]
if len(messages) and messages[0]["role"] == Role.SYSTEM:
system = messages.pop(0)["content"]
else:
system = None
if len(messages) % 2 == 0:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="Only supports u/a/u/a/u...")
for i in range(len(messages)):
if i % 2 == 0 and messages[i]["role"] not in [Role.USER, Role.TOOL]:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="Invalid role")
elif i % 2 == 1 and messages[i]["role"] not in [Role.ASSISTANT, Role.FUNCTION]:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="Invalid role")
elif messages[i]["role"] == Role.TOOL:
messages[i]["role"] = Role.OBSERVATION
tool_list = request.tools
if len(tool_list):
try:
tools = json.dumps([tool_list[0]["function"]], ensure_ascii=False)
except Exception:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="Invalid tools")
else:
tools = ""
async with semaphore:
loop = asyncio.get_running_loop()
return await loop.run_in_executor(None, chat_completion, messages, system, tools, request)
def chat_completion(messages: Sequence[Dict[str, str]], system: str, tools: str, request: ChatCompletionRequest):
if request.stream:
generate = stream_chat_completion(messages, system, tools, request)
return EventSourceResponse(generate, media_type="text/event-stream")
responses = ollama.chat(model=request.model,
messages=messages,
options={
"top_p": request.top_p,
"temperature": request.temperature
})
prompt_length, response_length = 0, 0
choices = []
result = responses['message']['content']
response_message = ChatCompletionMessage(role=Role.ASSISTANT, content=result)
finish_reason = Finish.STOP if responses.get("done", False) == True else Finish.LENGTH
choices.append(
ChatCompletionResponseChoice(index=0, message=response_message, finish_reason=finish_reason)
)
prompt_length = -1
response_length += -1
usage = ChatCompletionResponseUsage(
prompt_tokens=prompt_length,
completion_tokens=response_length,
total_tokens=prompt_length + response_length,
)
return ChatCompletionResponse(model=request.model, choices=choices, usage=usage)
def stream_chat_completion(
messages: Sequence[Dict[str, str]], system: str, tools: str, request: ChatCompletionRequest
):
choice_data = ChatCompletionResponseStreamChoice(
index=0, delta=ChatCompletionMessage(role=Role.ASSISTANT, content=""), finish_reason=None
)
chunk = ChatCompletionStreamResponse(model=request.model, choices=[choice_data])
yield jsonify(chunk)
for new_text in ollama.chat(
model=request.model,
messages=messages,
stream=True,
options={
"top_p": request.top_p,
"temperature": request.temperature
}
):
if len(new_text) == 0:
continue
choice_data = ChatCompletionResponseStreamChoice(
index=0, delta=ChatCompletionMessage(content=new_text['message']['content']), finish_reason=None
)
chunk = ChatCompletionStreamResponse(model=request.model, choices=[choice_data])
yield jsonify(chunk)
choice_data = ChatCompletionResponseStreamChoice(
index=0, delta=ChatCompletionMessage(), finish_reason=Finish.STOP
)
chunk = ChatCompletionStreamResponse(model=request.model, choices=[choice_data])
yield jsonify(chunk)
yield "[DONE]"
return app
if __name__ == "__main__":
app = create_app()
uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("API_PORT", 8000)), workers=1)
测试
1 | curl --location 'http://127.0.0.1:8000/v1/chat/completions' \ |